Improving long-horizon planning through harness engineering
Lugman Hussain Khan
DeepPlanning is a benchmark for long-horizon agentic planning released by the Qwen team. Its Travel subset asks an agent to build a multi-day itinerary that satisfies user preferences, respects implicit environment constraints like opening hours and ticket availability, and stays inside an explicit budget. Each task is graded on four metrics: a Commonsense Score, a Personalized Score for user-specified constraints, a Composite Score, and a Case Accuracy that only awards a 1 when both the Commonsense and Personalized scores are perfect.
This post walks through the harness changes we applied to Claude Sonnet 4.6 (high reasoning) on the Travel subset, and what each change did to case accuracy.
Setting the baseline
We started with the benchmark's default agent loop and default tool set. Sonnet 4.6 with high reasoning scored 20.8% case accuracy. The Composite score was 73.2%, which means the model satisfied many individual checks but rarely landed every check on a single task.
Inspecting the failed traces surfaced four recurring patterns:
- Hallucinated prices. The model recalled prices from earlier tool results and occasionally restated them with small errors. That broke the cost calculation check.
- Sorting under pressure. When the user query implied a sort (lowest price, earliest departure), raw tool results came back unsorted and the model tried to sort them mentally. Wrong picks followed.
- Personalization gaps. Multi-clause user requirements (washing machine, dryer, three-star hotel, departure time window) were only partially satisfied. One or two clauses would slip through.
- Commonsense violations. Repeated attractions across days, missing intra-city travel segments, and other structural issues that the benchmark's commonsense dimensions catch.
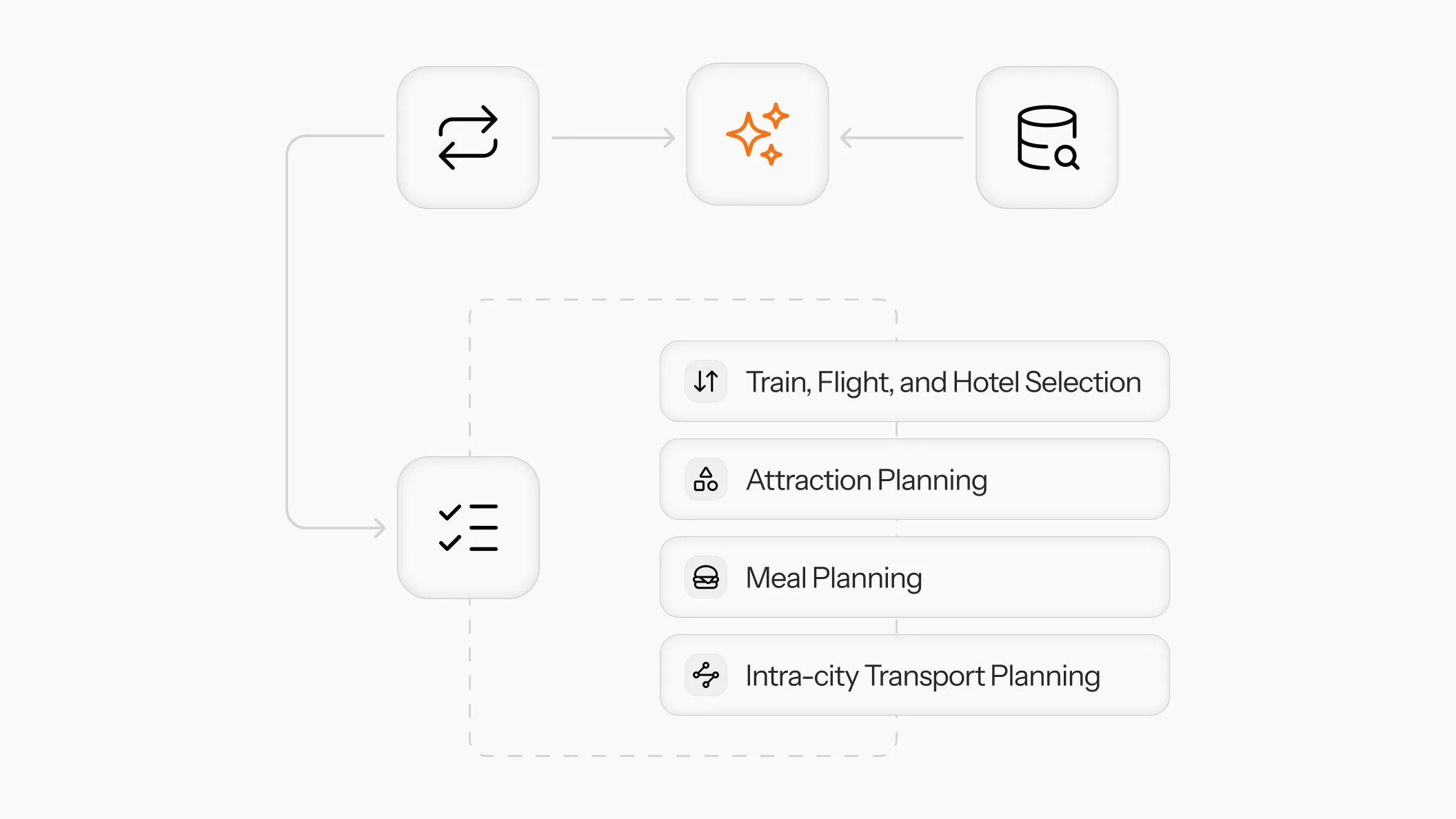
Giving the model a draft pad and a checklist
We made three changes at once.
- A
sort_keyparameter on retrieval tools. Pushing the sort criterion to the tool removes the need for the model to sort across long result lists in working memory. - A
write_draft_plantool. This is a scratchpad. The model writes its proposed itinerary and the tool acknowledges receipt. The point is to force the model to externalize its plan before any validation phase. - A
fetch_checklisttool. It returns the benchmark's commonsense checklist one section at a time, so the model can drive a section-by-section verification loop. The system prompt was updated to require this loop after the draft plan is written.

Here is what the meals section of the checklist looks like:
{
"meals": [
"Ensure names of all locations and entities match the tool results.",
"Strictly schedule all meal activities for 1 to 2 hours.",
"Ensure scheduled meal times fall entirely within the specific restaurant's open hours.",
"Maintain at least a 2-hour interval between lunch and dinner.",
"Include exactly 2 meals (both a lunch and a dinner) on every full non-transfer day.",
"Strictly follow the arrival/departure meal rules based on the transfer day schedule.",
"Include all user-specified must-eat venues exactly as specified.",
"Ensure all chosen restaurants are unique across different days.",
"Correctly omit breakfast from the itinerary.",
"Do not select any restaurant marked as 'Temporarily Closed'."
]
}
We considered adding a todo-style task tracker but dropped it. Trace analysis showed that Sonnet 4.6 already broke tasks into ordered steps without prompting, so an explicit todo tool would have been redundant.
After these changes, case accuracy moved from 20.8% to 47%. That put the configuration in second place on the benchmark, behind Claude Opus 4.6 with max reasoning at 61.5%.
When the model starts checking boxes without looking
Traces from the 47% run surfaced a new failure mode. By the time the validation phase started, the average context length was around 65,000 tokens. The model would walk through the checklist and mark items as passing without actually re-reading the draft and checking. Obvious violations (a budget overrun visible directly in the plan, an attraction listed twice across days) were stamped as compliant.
The issue was not the existence of a checklist. It was that asking the same in-context model to audit its own long trajectory was unreliable. The validator needed a clean working context for each check.
Splitting validation into focused parallel checks
We changed write_draft_plan so that on submission, the harness automatically runs validation in the background and returns only the failed checks. The agent loop then either revises and resubmits, or, when no checks fail, treats the plan as final.
Validation uses the same model (Sonnet 4.6) but fans out into parallel calls by checklist section. Each parallel call receives:
- The validation instruction for that section.
- The draft plan as written.
- The checklist for that specific section only.
- The tool calls and their results that are relevant to that section. Transport and hotel checks see transport and hotel queries. Attraction and meal checks see attraction and restaurant queries. Intra-city travel checks see route queries.
Each validator runs against a short, focused context built specifically for its section. There is no long trajectory to skim past and no incentive to rubber-stamp. Results from the parallel validators are aggregated, and any failed checks are returned to the agent loop for revision.

Putting it all together
With the validation harness in place, Claude Sonnet 4.6 reached 65.8% case accuracy on the Travel subset, with a Commonsense score of 97.2, a Personalized score of 81.7, and a Composite score of 89.4.
For comparison:
| Configuration | Commonsense | Personalized | Composite | Case Accuracy |
|---|---|---|---|---|
| Sonnet 4.6 baseline | 83.9 | 62.5 | 73.2 | 20.8 |
| GPT-5.2 high | 88.5 | 83.3 | 85.8 | 35.0 |
| Opus 4.6 max | 86.1 | 80.3 | 83.2 | 61.5 |
| Sonnet 4.6 + Custom Harness | 97.2 | 81.7 | 89.4 | 65.8 |
The harness brought Sonnet 4.6 above Opus 4.6 with max reasoning on case accuracy, at a lower per-call cost.
This exercise was a reminder that agent performance often plateaus because of harness design, not model capability. Sonnet 4.6 already knew how to plan a trip. What it lacked was a clean way to write that plan down before validating it, and a validator that was not drowning in its own history.
Once we offloaded sorting to the tools, forced a draft step, and ran parallel checks in isolated contexts, the model started passing tasks it had been failing consistently. The gap between a 73 percent composite score and a 65.8 percent case accuracy is the gap between mostly right and actually done. Closing that gap is a harness problem.